

I gave an AI agent OAuth access to my hospital. It worked on the first try.
The day a $15/month open-source agent pulled my full medical history out of a Telegram chat and gave me an AMC level patient summary.

View all my published articles
I gave an AI agent OAuth access to my hospital today.
The whole thing happened in a Telegram chat. No API integration. No partnership. No six-month enterprise procurement cycle. No code written on my end to talk to the hospital. I texted a bot. The bot handed me a link. I tapped a single consent screen on MyChart and typed in a six-digit code. The agent ran the SMART on FHIR handshake itself, decrypted the patient-pull payload, and dropped my full medical history onto a Linux box in Azure.
Total cost to run the stack: ~$30 a month. Time from “let’s try it” to “the agent has the records”: about five minutes.
It worked on the first try.
If you’ve spent any time in healthcare IT, you know how unusual that sentence is.

The entire human-side ceremony: open a text, tap a link, type six digits. Everything else is the agent talking to the hospital.
What I actually did
The agent is part of Tula, an open-source health agent I’ve been building for the last several weeks. It’s a collection of skills that run on top of OpenClaw, a self-hosted agent runtime. One of those skills, health-records, is a SMART on FHIR client, the open standard that hospitals are legally required to support under the 21st Century Cures Act for patient-initiated data access.
From the outside it looks like a chat conversation. From the inside it’s a lot of plumbing that nobody had to write today because someone wrote it five years ago and I stood on their shoulders.
Here’s the actual flow:
I sent the agent a message: “pull my records from Beverly Hospital.”
The skill spun up a one-time SMART on FHIR session, registered a redirect, and texted me back a URL.
I tapped the URL, landed on MyBILH Chart, authenticated, typed the 2FA code from my phone, and clicked “allow.”
The hospital sent back an encrypted bundle containing every observation, condition, medication, lab result, and provider note in my chart.
The agent decrypted it locally (the private key never leaves my VM), wrote it to disk as FHIR R4 JSON, and was ready to reason longitudinally about my health.
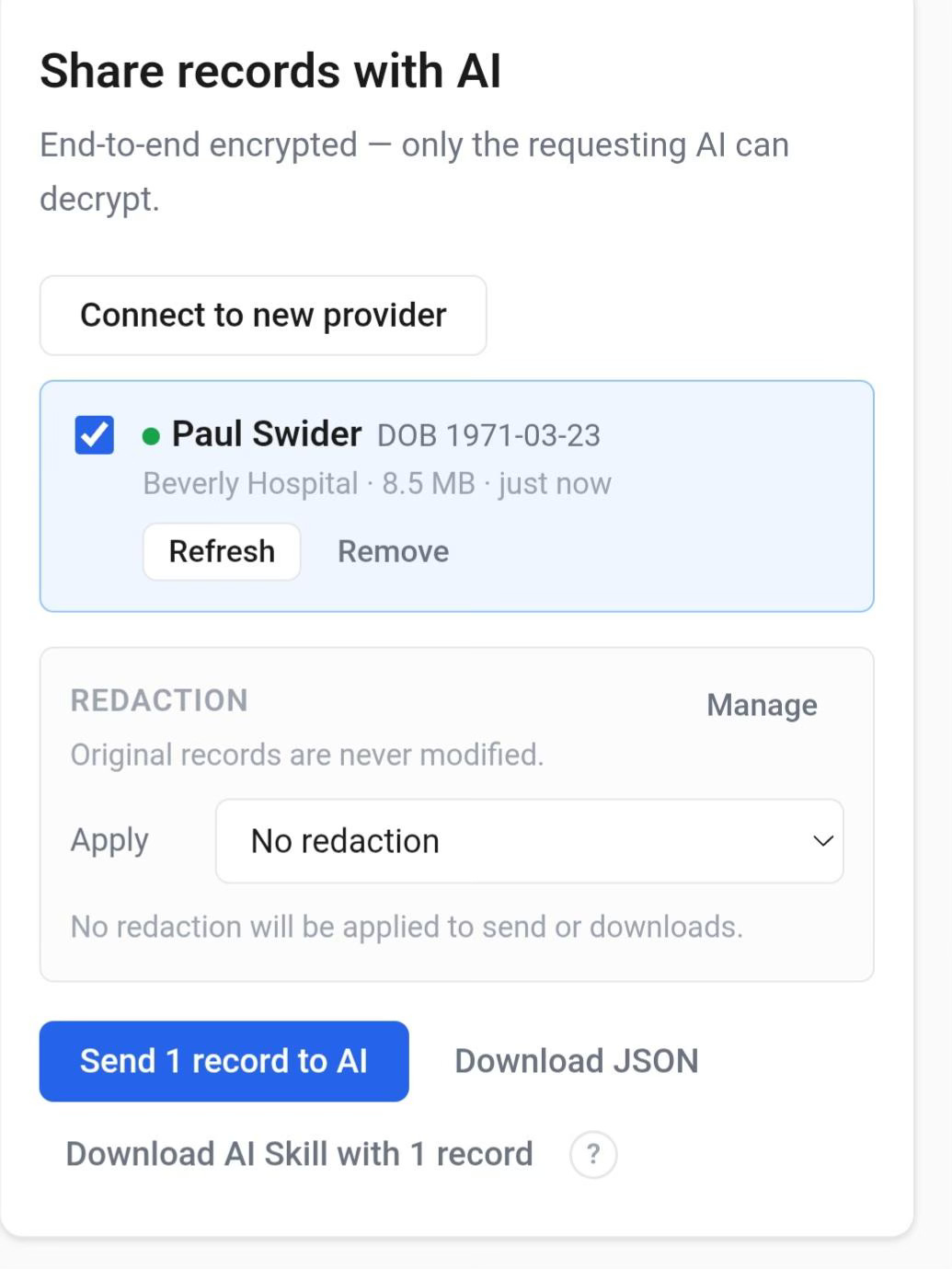
8.5 MB of FHIR-formatted history from Beverly Hospital. End-to-end encrypted from the moment it leaves the EHR until it lands on the VM. The original records are never modified; redaction is opt-in on the patient side.
A1c trends across years. Every blood pressure measurement on file. Every clinical note that mentions sleep apnea or thyroid or hereditary risk factors. (The reasoning step itself uses whatever LLM is configured: Claude or Gemini against their HIPAA-eligible API tiers, or local MedGemma if you want the entire inference stack airgapped.)
The whole stack costs about $30 a month to run. The hospital integration cost: $0.
Why this is harder than it sounds
A lot of healthcare AI demos use synthetic data. Synthetic data is fine for showing a UI, but it doesn’t prove anything about whether your agent can survive contact with a real hospital’s auth flow, a real Epic FHIR endpoint, a real OAuth dance that’s been quietly tweaked twelve times since you last looked.
Real medical records have real edge cases. Provider notes with instructions you didn’t anticipate. PDF attachments that look textual but are actually scanned images. Date fields in seventeen different formats. LOINC codes that look standardized until you check four different lab vendors and discover they’re not. Medication entries that omit the dose, the route, or the indication, depending on which subsystem wrote them. Results vary by EHR too. Epic’s FHIR endpoints are the strongest; some hospitals on other systems return spottier notes or imaging metadata.
The reason this matters: you can spend two years and several million dollars building a “healthcare AI” product that works perfectly against synthetic data and then collapses the first time someone forwards an actual lab PDF.
Tula was built to survive contact with real records from day one. The health-records skill is a Node ESM port of Joshua Mandel’s health-skillz. Mandel’s the technical co-founder of the SMART project and one of the people who built SMART on FHIR into something hospitals actually implement. His original code has been battle-tested against real Epic, Cerner, and Athena endpoints. I carried his MIT license forward with full attribution and ported the patterns into Tula’s skill format.
Today I pointed it at my own hospital. It pulled the records. The agent now knows me.
Why this matters
Patient access to medical records has been a legal right since HIPAA in 1996. It became a teeth-bearing legal right under the 21st Century Cures Act information-blocking rule, which took effect in 2021 and made it illegal for hospitals to obstruct patient-initiated data sharing. Most patients still have no idea this is a button they can press.
The reason is simple: nothing useful happens after you press the button. You get a clinical-systems dump with eight years of lab values, no context, no narrative, no synthesis. It’s like being handed your tax returns in their raw IRS-form state and told “good luck.”
Put an open-source AI agent on the other side of that pull, and everything changes:
You get your records, on your hardware, on your time, without anyone in between.
You can ask longitudinal questions: “How has my kidney function changed since my mother’s diagnosis?” The agent has the data, the context, and you.
You can forward documents from any provider (labs, imaging, EOBs, prescriptions, portal messages) and have them automatically extracted into the same FHIR data model.
Your providers can change. Your hospital can change. Your EHR can change. The agent doesn’t care. The data follows you.
This is the inversion of the default state of healthcare in the United States. The default is that your records live in your provider’s system and you visit them. The agent makes your records live with you, and your providers visit them.
What’s open and what isn’t
Tula is open source under the Apache License 2.0 (as of yesterday, relicensed from MIT to add explicit contributor patent grants for downstream consumers). Anyone can deploy it. Anyone can build on it. The deployment guide is in the repo; I wrote it during a real deployment session, including every error I ran into and how I fixed it. It runs on Azure, on bare metal, even on a Raspberry Pi at the high end if you’re patient.
Running it on your own infrastructure means you own the security: keep the VM patched, encrypt the disk at rest, scope OAuth tokens narrowly and revoke them after the pull, and lock down the email channel. The full threat model and defense-in-depth posture is in docs/security-model.md.
There’s a commercial side to this too. RealActivity (the company I run) is building Aria, a hospital-scale platform that runs one Tula agent per patient under multi-tenant identity, SSO, audit, compliance, BAA chain: everything a hospital needs to deploy this to thousands of patients at once. We call the architecture a Patient Swarm: many specialized, patient-centered agents operating in parallel, each with isolated state, coordinated by a shared control plane. The clinical reasoning is the same as personal Tula; what Aria adds is scale, identity, and compliance.
Personal Tula stays open, free, and complete on its own. Aria is built on top of it. The same skill that pulled my records this afternoon will run inside every patient cell in a hospital deployment. The boundaries are documented in the repo’s OPEN_CORE.md.
Where to find it
The skill that pulled my records today: skills/health-records
Deployment guide: docs/deployment-guide.md
The upstream that made it all possible: jmandel/health-skillz
If you build something useful with this, I want to hear about it. If you’re a hospital and want to talk about Aria, the contact info is in the repo. If you’re a patient with a chronic condition or caregiving load and you want to deploy this yourself, the deployment guide was written for someone with no Linux experience, by someone who had no Linux experience three months ago.
The internet was supposed to give us this in 2005. It’s twenty-one years late.
Better late than never.
Paul
Tula is open-source software for personal health data organization and health literacy. It is not a medical device, not FDA-cleared, and not intended to diagnose, treat, cure, or prevent any disease. Talk to your doctor about anything that matters.